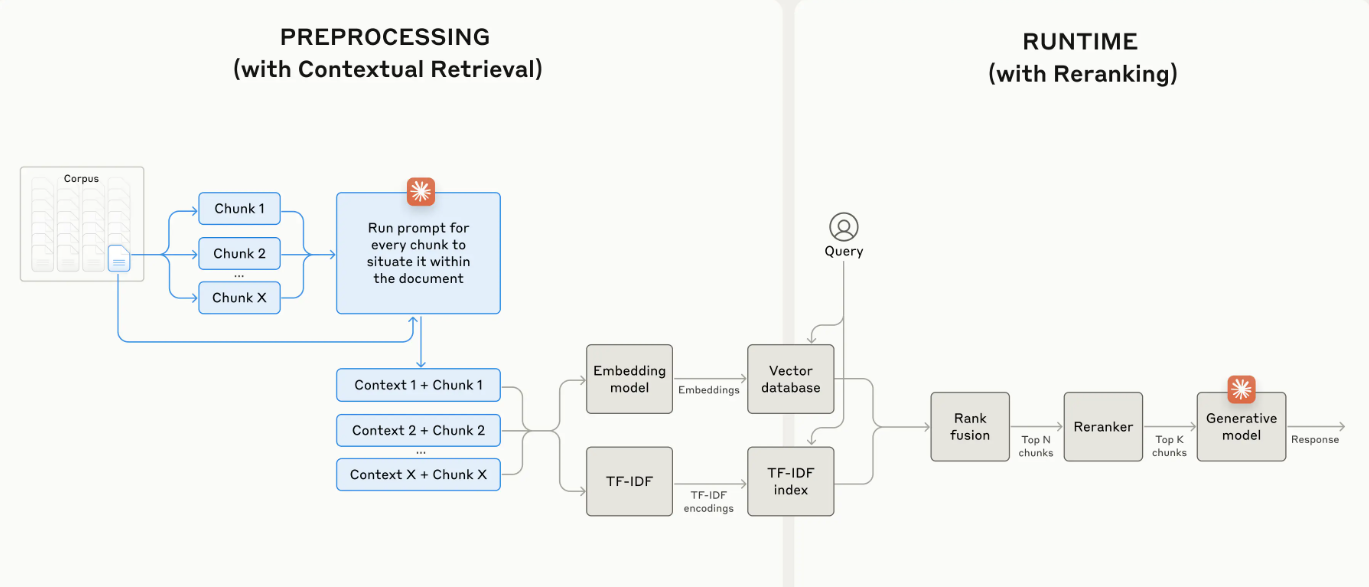
In traditional RAG, documents are typically split into smaller chunks for efficient retrieval. While this approach works well for many applications, it can lead to problems when individual chunks lack sufficient context.
To address this Anthropic has introduced Contextual Retrieval, which solves this problem by prepending chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”).
Let’s first understand how we can build RAG solutions more accurately, which retrieve the most applicable chunks by combining the embeddings and BM25 techniques. It usually start with following steps: * (1) Break down the knowledge base (the “corpus” of documents) into smaller chunks of text, usually no more than a few hundred tokens; * (2) Create TF-IDF encodings and semantic embeddings for these chunks; * (3) Use BM25 to find top chunks based on exact matches; * (4) Use embeddings to find top chunks based on semantic similarity; * (5) Combine and deduplicate results from (3) and (4) using rank fusion techniques; * (6) Add the top-K chunks to the prompt to generate the response.
By leveraging both BM25 and embedding models, traditional RAG systems can provide more comprehensive and accurate results, balancing precise term matching with broader semantic understanding.
Now let’s implement Contextual Retrieval, by writing a prompt that instructs the model to provide concise, chunk-specific context that explains the chunk using the context of the overall document. The resulting contextual text, usually 50-100 tokens, is prepended to the chunk before embedding it and before creating the BM25 index. Retrieval accuracy can further be improved using a reranking model. Whereas Prompt Caching to reduce the costs of Contextual Retrieval as you don’t need to pass in the reference document for every chunk.
During evaluation Contextual Retrieval reduces the number of failed retrievals by 49% and, when combined with reranking, by 67%. Further, Contextual Embeddings reduced the top-20-chunk retrieval failure rate by 35% (5.7% → 3.7%). These represent significant improvements in retrieval accuracy, which directly translates to better performance in downstream tasks.
Blog : https://www.anthropic.com/news/contextual-retrieval
Code : https://github.com/anthropics/anthropic-cookbook/blob/main/skills/contextual-embeddings/guide.ipynb